Introduction
In this project, our group aimed to develop a classification model that correctly classifies each posting in the video gaming category in Craigslist into a corresponding brand to enhance user experience and the company’s key business performance.
-
Tools / Libraries used: Python / beautiful soup, pandas, nltk, scikit-learn, keras, etc.
-
Dataset: Web Scrapped / titles and reviews of posts in Craiglist / 3011 rows * 8 columns
-
Analyses Performed: Web Scrapping, Data Cleaning/Manipulation, Keyword Extraction, Text Representation(Tokenization, Lemmatization, Vectorization), Machine Learning(Naive Bayes, Logistic Regression, Random Forest, SVC, Neural Network), Deep Learning(Recurrent Neural Network), Validation(Confusion Matrix), and Business Insights
Analysis
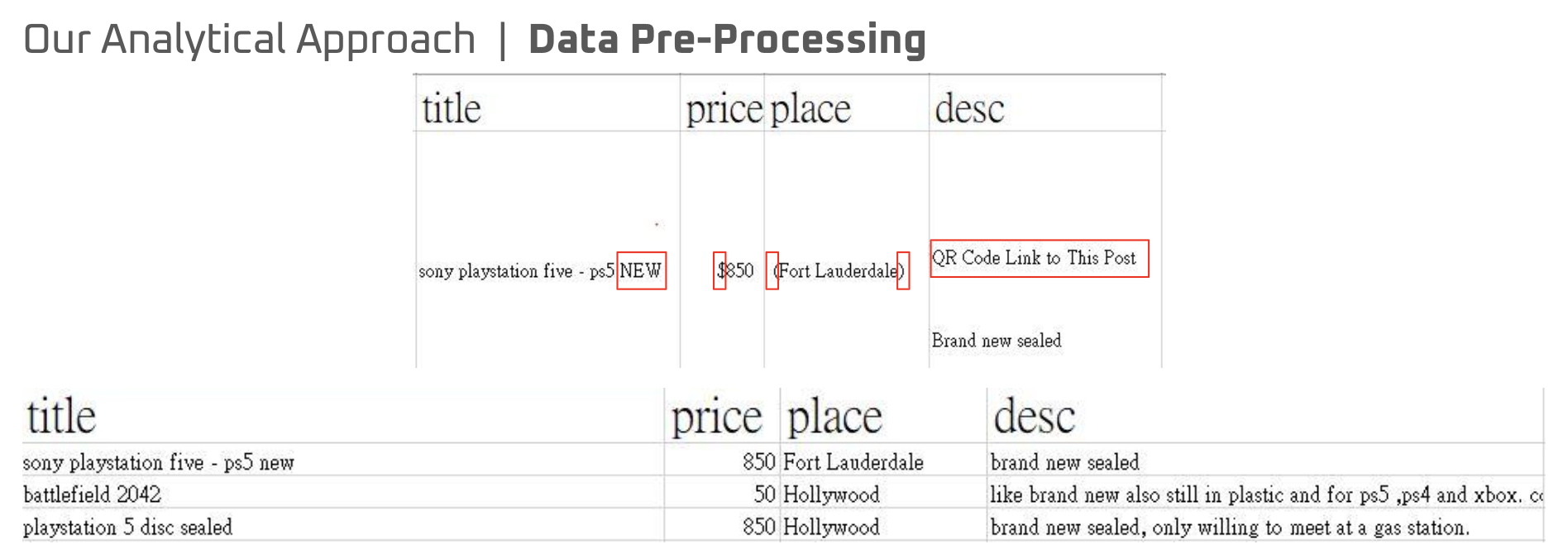
FIrst, we performed web-scrapping in the video gaming cateogry in Craigslist. We collected posting id, datetime, city, title, price, place, and description. Then we cleaned the data by removing dollar sign in price and parentheses in place, making the description column in one line, and lowering the title case.
[Data cleaning]
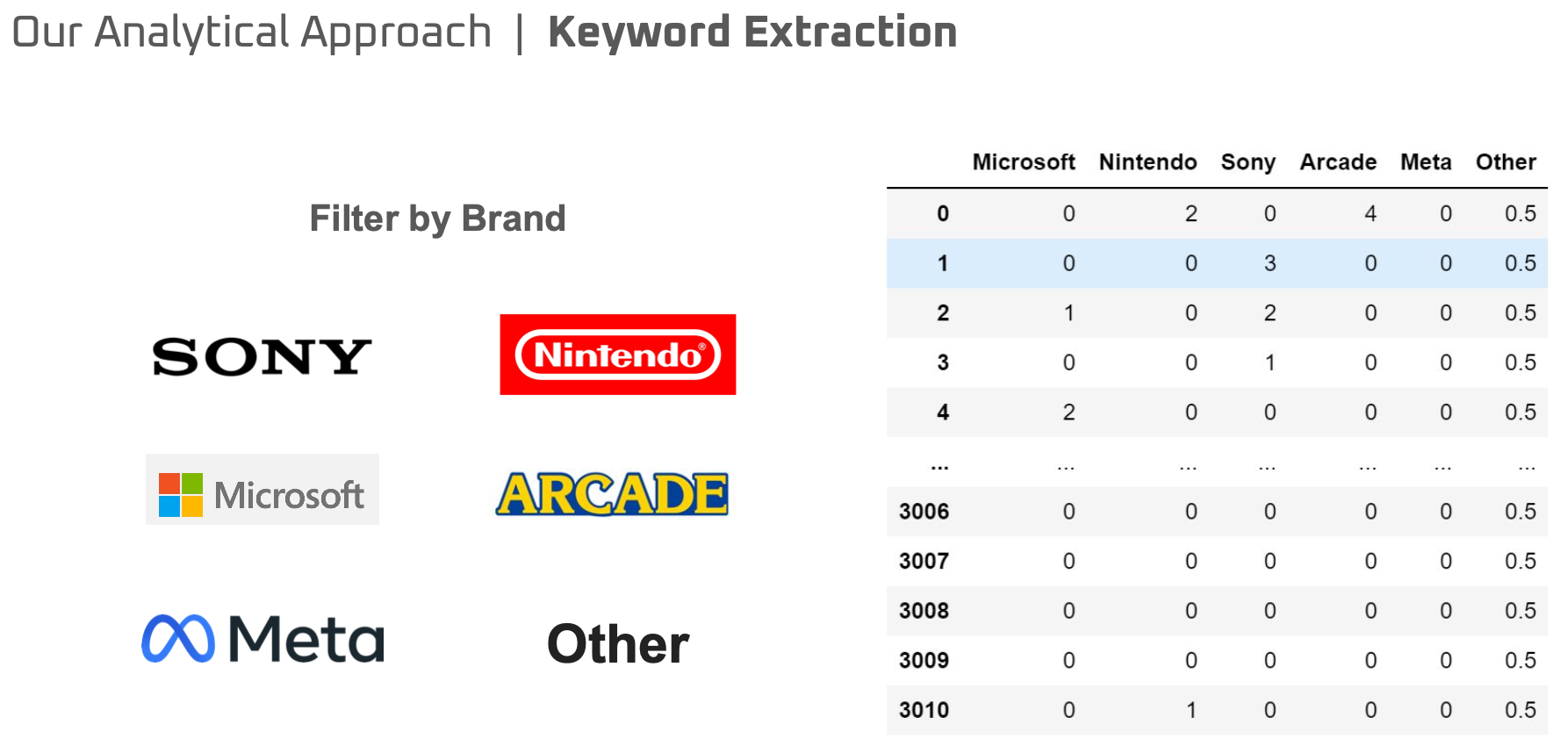
Then to create target variables more efficiently, we wrote codes that count the number of words that are relevant to each brand, to assign each post to a corresponding category. For example, the first row in the table has the higest score in Aracde (4), so we assign that post to Arcade category.
[Creating target variables - Keyword extraction]
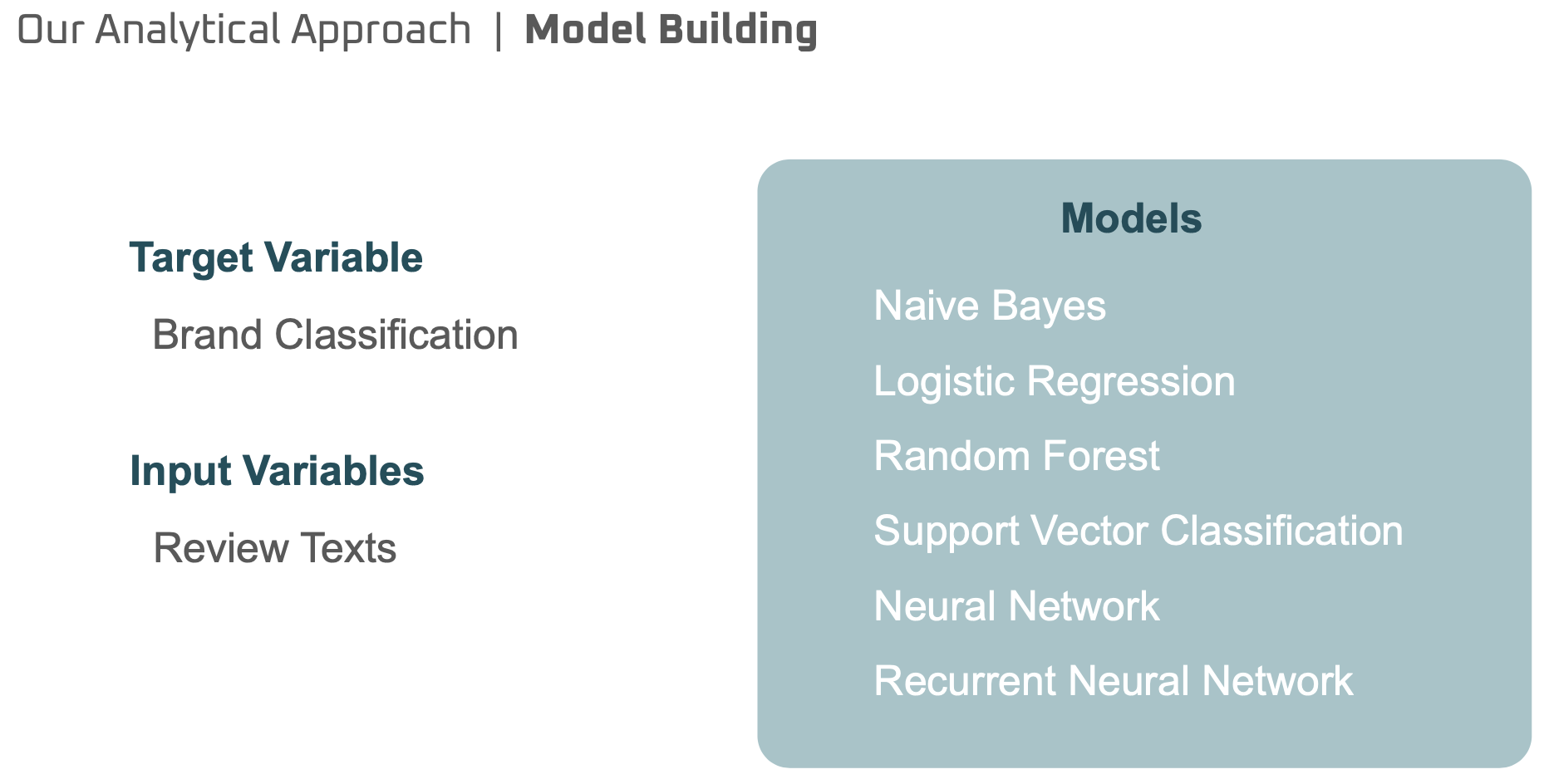
Next, using predictor variables(title + description) and response variables(corresponding brands), we built 6 different models. We first vectorized the predictor variables from text to numerical values using TFIDF vectorization after tokenizing, lemmatizing and removing stop-words and punctuations. Then we splitted the dataset into train(70%) and test(70%) setsto train and evaluate our models.
[Model building]
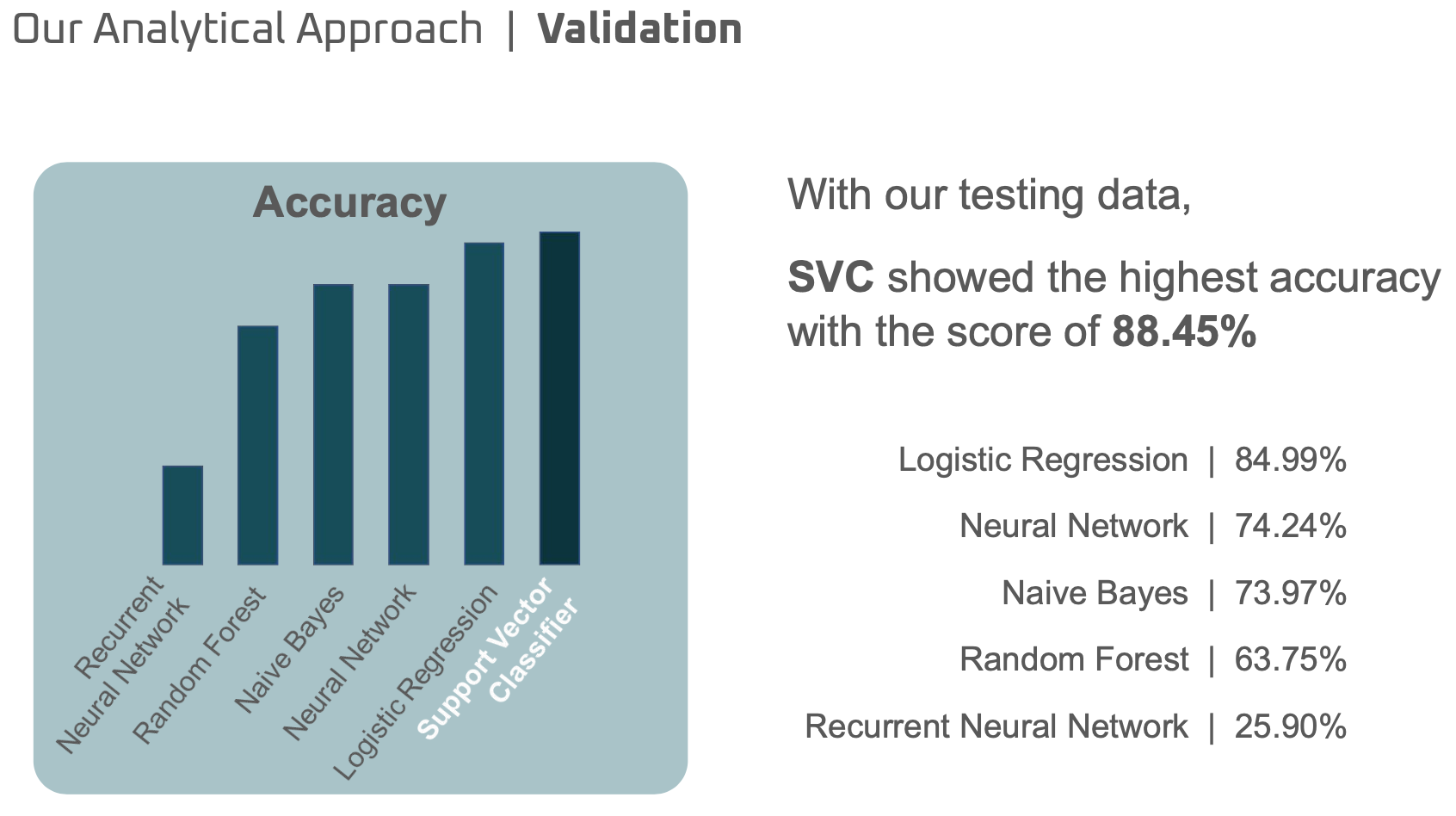
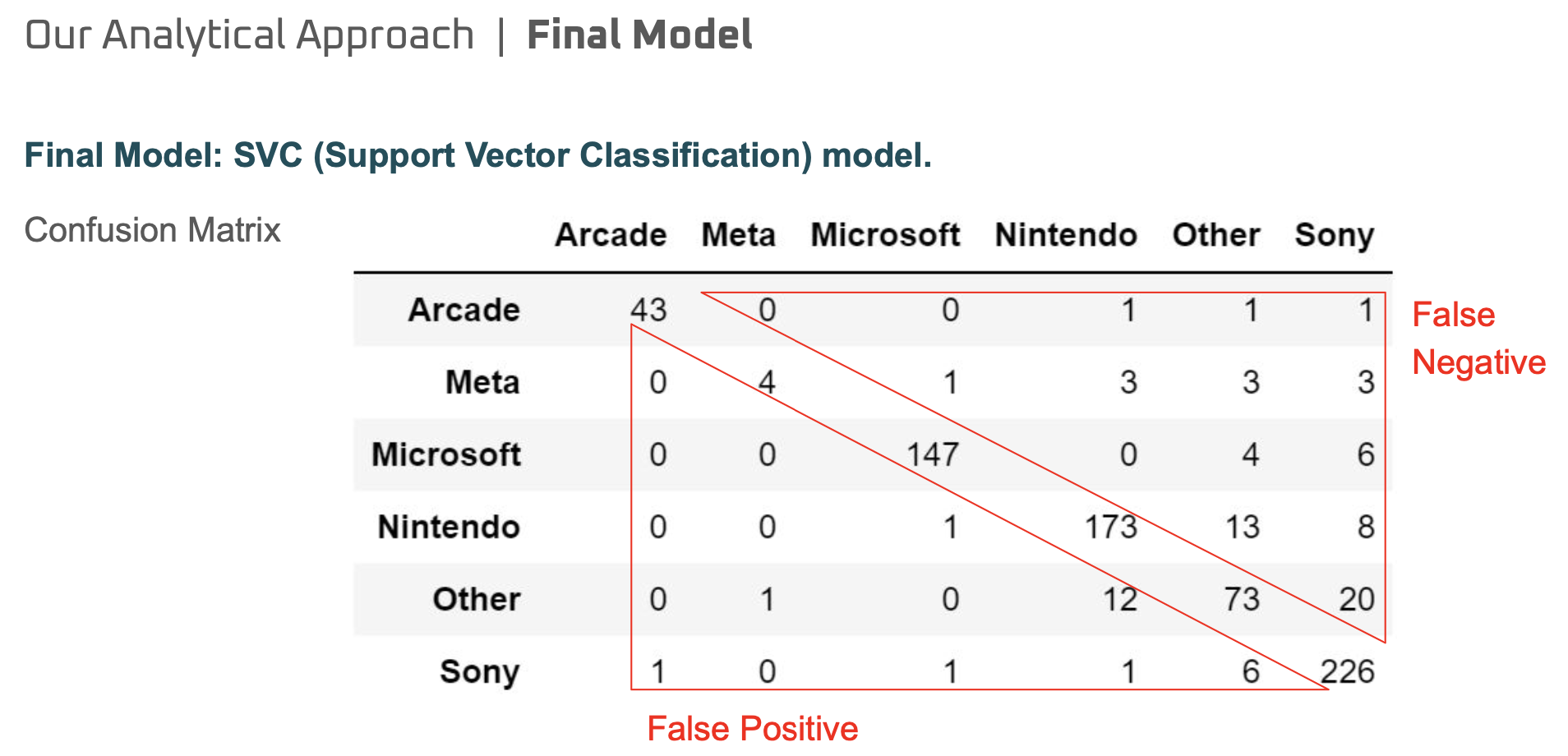
From the result, SVC model showed the higest accuracy with the score of 88.45%. From the confusion matrix of the SVC model, we can evaluate how model predicted each brand correctly.
[Model performance]
[Confusion matrix]
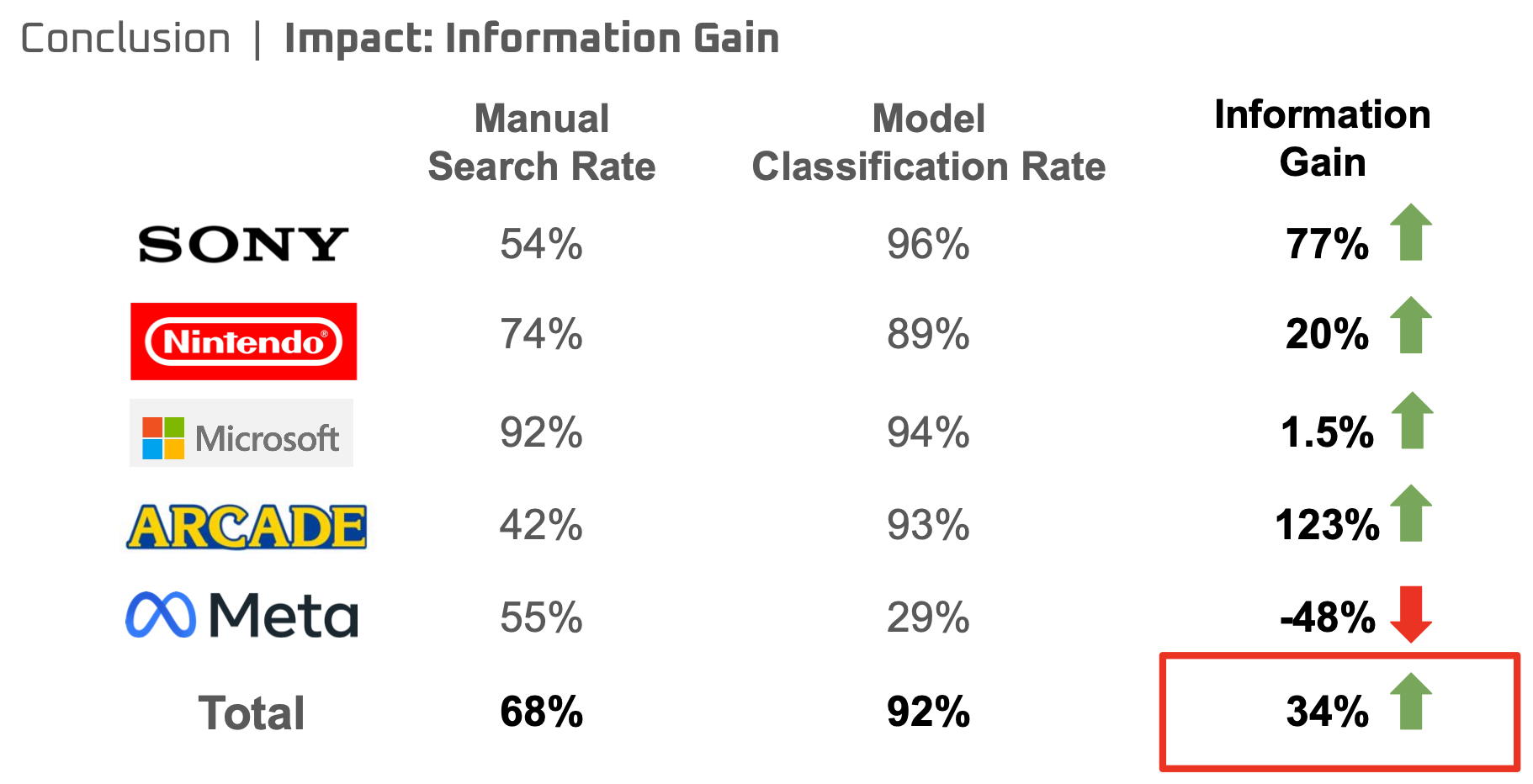
Our model generated huge information gain by 34%. The website's search rate is 68% and our model classification rate is 92% (excluding others). It shows that our best model would provide more correct results and minimize information loss on the searches that users performed on the website. Therfore, we would expect that our model would contribute to an increase engagement of users with the webiste, leading to growth in retention rate and potentially generating more revenue.
[Information gain comparison]
## Details of Codes and Model Building Process
{kind=link}

Design Database and SQL queries to enhance KPI measurement
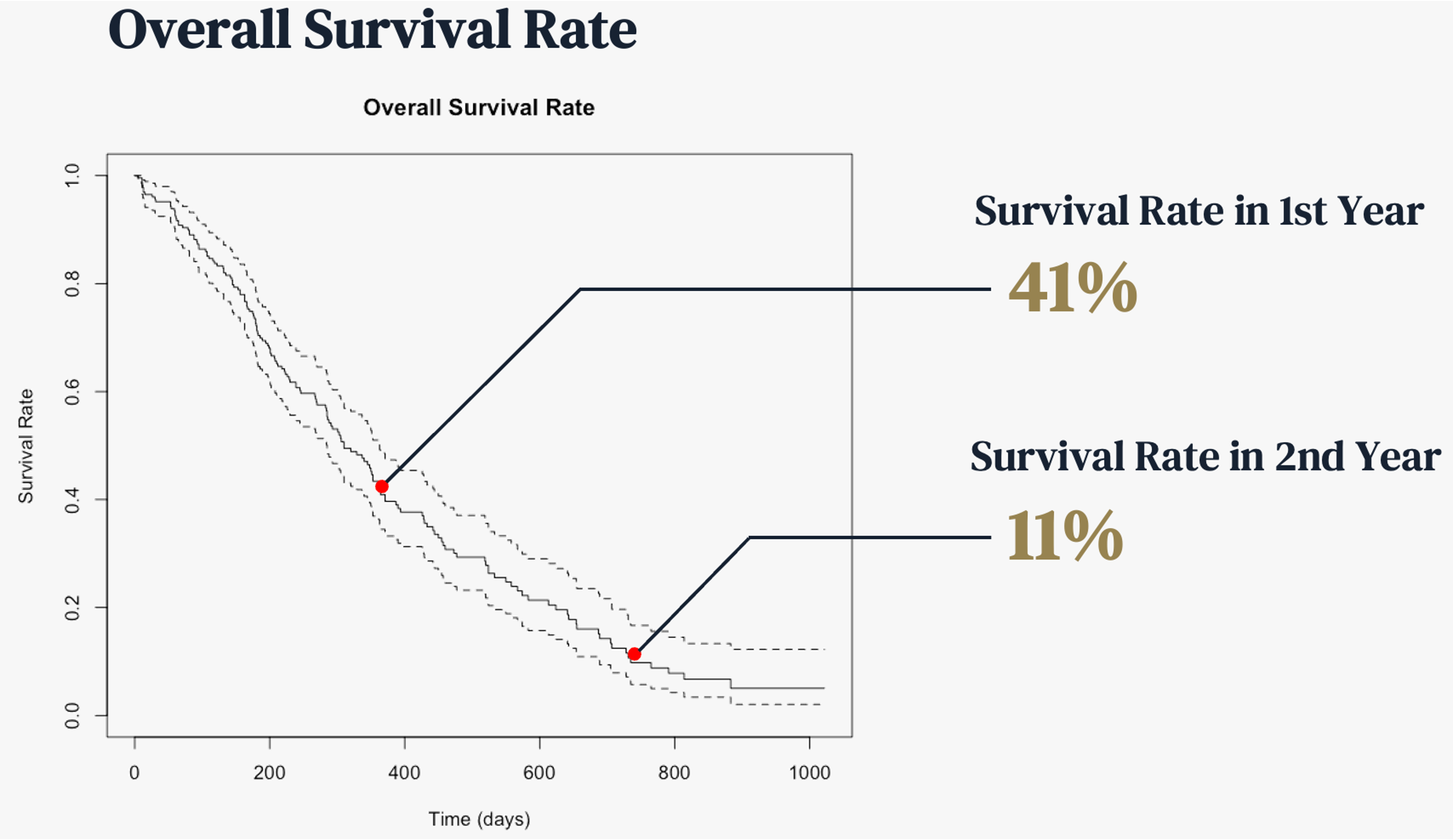
Lung Cancer Survival Analysis